AI Danger & The Alignment Problem: A 10 minute crash-course


In 2023, Nobel Prize winners, AI scientists, and CEOs of leading AI companies stated that “mitigating the risk of extinction from AI should be a global priority.”
What the big companies are currently doing: Building powerful AI models.
WHY: The companies and leading laboratories are not building these AI models for you to pay 20 bucks/month to have them do your taxes or homework. That's the testing phase, and to some degree, we are the testers.
The real commercial goal for many companies is probably charging 2000-10K dollars per month for a super-employee that never eats or sleeps and that works 10x faster than you do.
The outspoken end goal is to end up with the most powerful technology in the world, supersmart AI. What many company leaders secretly dream of, is that their company will create the first trillionaire, and potentially make their company more powerful than most countries.
The story is that they would use this power to make the world better. In reality however, various AI models are already incorporated into weapon systems, (and planned for use in nuclear weapons support systems, like threat monitoring,) as well as in financial trading, marketing, and other profitable uses.
Of course, we have notable examples of research successes sponsored by big companies too, like AlphaFold, sponsored (and owned) by Alphabet/Google. AlphaFold has revolutionized protein folding research with implications for medicine and biology in general.
Still, solving protein folding is the only thing it does: it is trained to be a narrow AI model, not a general one. The goal of OpenAI (ChatGPT), Google (Gemini), Anthropic (Claude), xAI (Grok) and Meta AI, is to build general AI.
Current AIs are built a bit like brains
How they work: The current models than run ChatGPT, Gemini and so on, are based on neural networks and mimic brain functions. More specifically, they mirror neural connections in the brain in order to generate new outputs.
"So what?" skeptics say. "It is still just a soulless computer doing simple prediction style calculations. The current frontier AIs are not much more than fancy tools."
This is debatable. This was perhaps correct for early neural networks, but this is not necessarily correct for current large models using transformer technology.
Modern frontier LLMs (large language models), like ChatGPT, are more like huge, alien brains. They run on massive matrix multiplications, mapping and tweaking data points in high-dimensional vector space. The scaling makes a difference. It allows for emergent properties and it makes the AI inscrutable.
Still, the criticism is somewhat fair. Current AIs owe their success to imitating neural networks, but existing models are still less complex than brains. For example: a brain has 60 to one hundred trillion neural connections. Leading AI models still doesn't match this level of complexity with their own parameter counts.
The largest parameter counts are now listed in the trillions though, whereas the first “large” models only had millions of parameters.
Another important fact to consider, is that these "AI brains" already think faster than our neurons fire. They also have access to vastly more information than we do. New AI designs could make them more sophisticated.
The current AIs also consume much more energy than a human brain does, which is a problem for scaling. This is why some people don’t see the current models scale all the way to human intelligence. But it does cause large environmental problems and accelerates global warming.
Either way, technology is pushing forward very rapidly. What was unthinkable ten years ago is now reality. Yes, current AI models still have significant limitations, (such as struggling to generalize outside of training data,) but there is no reason to believe that clever engineers and researchers will not invent new ways to improve them.
Soon, the big companies say, their AIs will become more intelligent than human minds.
The science- and engineering community as a whole, mostly agrees that this is not just possible, but highly likely.
Furthermore, "smarter than a human" doesn't necessarily mean the difference between a child and an adult, but it could be something more like the difference between a rat and a human. If you CAN make something smarter than a human, nothing says there is a limit just above human level intelligence.
They only disagreement is when.
The two major safety problems with current AI models and with AGI:
- We don't understand how they work or think in detail* (or what they may end up like).
- We don't know how to make them always do what we want them to do.
In fact, we can't make them want to do anything in the same sense that we want things. We just train them with reward modelling until they seem helpful, most of the time.
*We can no longer understand what large language models think by peeking inside, just like we can't understand in detail how a human thinks by looking inside its brain. It's just too complex.
The study of how to understand what's going on inside of the AI is known as interpretability and it is an active area of research. But just like neuroscience takes time to figure out (much longer than it takes to build nukes or AIs) we are not yet mind readers.
This is also why it is so hard to control what they do once we allow them to be turned on. We can't control a dog's brain either, but we can predict how it thinks and what it wants. Of course, a dog isn't even close to being as smart as we are, so we can still find ways to control it even if the training fails.
Solving the second problem (the control problem) seems to take priority.
However, even IF we solve the control problem, this actually creates new, serious problems.
Implication: Any person who controls one or several very powerful AIs will in turn become very powerful. And if we build a superintelligence, the superintelligence itself will become very powerful. In both cases, we need a way to make sure this power is not causing us harm.
The alignment problem
The alignment problem is basically this: How do we make rational agents do what we want them to do?
For humans, this is already very hard.
First of all, few of us know what we really want. Secondly, what we want is not always what's good for us. Thirdly, even when we know what we want and that it is good for us, it's easy to go wrong and make mistakes.
That's partly why humans have morals that guide us towards generally acceptable outcomes, and which prevent us from causing too much harm to each other in a vast range of situations. However, they are far from perfect, and they usually break down when someone gets too much power.
The problems of applying morality to power is exactly the kind of problems that needs to be considered when a human gets access to a powerful AI model, OR when we build an AI model and try to align it to be "good".
Problem 1: What makes a good person? What qualities would let us trust someone with awesome power?
Answer: We don't agree on any answers.
Problem 2: How do we make sure these qualities are actually transferred to this person? How do we make sure the person will apply these qualities?
Answer: We don't know.
Problem 3: How do we make sure the person in control of vast power will remain a good person over time?
Answer: Again, we don't know.
Think about children. We don't know how to raise our own children to be perfectly moral either. (And we can't even agree on what that even means.)
When you apply the same problems to an AI, it gets worse, because AIs are alien to us.
By the way, going back to the analogy of raising children, if we don't understand the AI well enough, how do we know that we are not raising the equivalent of a psychopath?
In fact, what reason do we have to believe that it's not a psychopath? After all, it doesn't have human emotions by default.
The Dangers of a Superintelligence
Now, if you are dealing with an agentic superintelligence (SI), your worries multiply and become much more serious than when dealing with a mere human agent. Why? For several reasons.
- You can't really fight something vastly smarter than yourself. Even if you build it yourself, you can't control it, without rendering it useless in the first place.
- The SI, unlike humans, may not depend on human society at all, like a human dictator would. It is not looking for social status, companionship or sex from humans, and it doesn't need the same things we do to survive (food, water, air...)'
- The SI may want many things that will indirectly cause harm to humans. If it doesn't care for humans (and why would it, unless we solved alignment?) then it will probably do those things even if they cause us harm.
Sidenote: I personally believe that even IF you manage to build a moral SI, if it is truly smarter than us, it can still end up being problematic. We don’t know what a “good” SI should look like or what it may do. I write about this in my trilogy: "The underexplored prospects of benevolent superintelligence".
Current paths forward
Right now, safety work is already lagging behind capabilities by a large margin.
First of all, the racing between China and USA is dangerous. Both are putting massive resources into creating useful AI models that they don't have the time to properly analyze and understand. USA in particular has little or no regulation.
This pushes safety to the sidelines. It also reminds me of the nuclear arms race: both sides are racing to be the first to build supersmart AI, even though both sides know there are major risks involved. This race needs to slow down and halt while there is still time.
For true superintelligence, the only safe solution according to me and many others, is to not build it. This is the stance taken by Nobel prize and Turing Award winner Geoffrey Hinton, Turing award winner and AI pioneer Yoshua Bengio, Stuart Russel, the co-author of the standard AI textbook ‘Artificial Intelligence: A Modern Approach’ and AI alignment pioneer and rationalist Eliezer Yudkowsky.
We need many years, perhaps decades, before we can even know whether such a thing can be built safely, on the first try.
Imagine if we had never built the atom bomb, and instead put that research into completely safe nuclear power. How different the world would be now.
For developing current AI models further, towards general agentic AI, so called AGI, the recommendation from safety experts and safety advocates is to slow down and put much more budget into interpretability and safety research. If we at least put 20 % of the investments into safety work, this would be a huge improvement.
We also need new laws and international governance on how it should be regulated. We should also study the psychological impact on AI users. We should not keep pushing capabilities until we have made sure the technology is safer than it currently is.
Finally, we should prepare for dramatic shifts in the labour markets. Many people will probably lose their jobs in the near future if AGI becomes mainstream, as is the current goal by its developers.
Universal basic income is one solution that is being floated for solving this issue. So far though, most money goes into funding AI, not preparing for unemployment or addressing the risks involved.
~
External material:
Links to videos with experts mentioned:
Nobel Prize: Geoffrey Hinton, Nobel Prize in Physics 2024: Banquet speech
TED: The Catastrophic Risks of AI — and a Safer Path | Yoshua Bengio | TED
BBC Newsnight (Eliezer Yudkowsky, September 22, 2025) Will Artificial Intelligence end the world? AI 'prophet of doom' speaks to Newsnight
Bonus: Expert forecast scenarios (by so called 'pessimists')
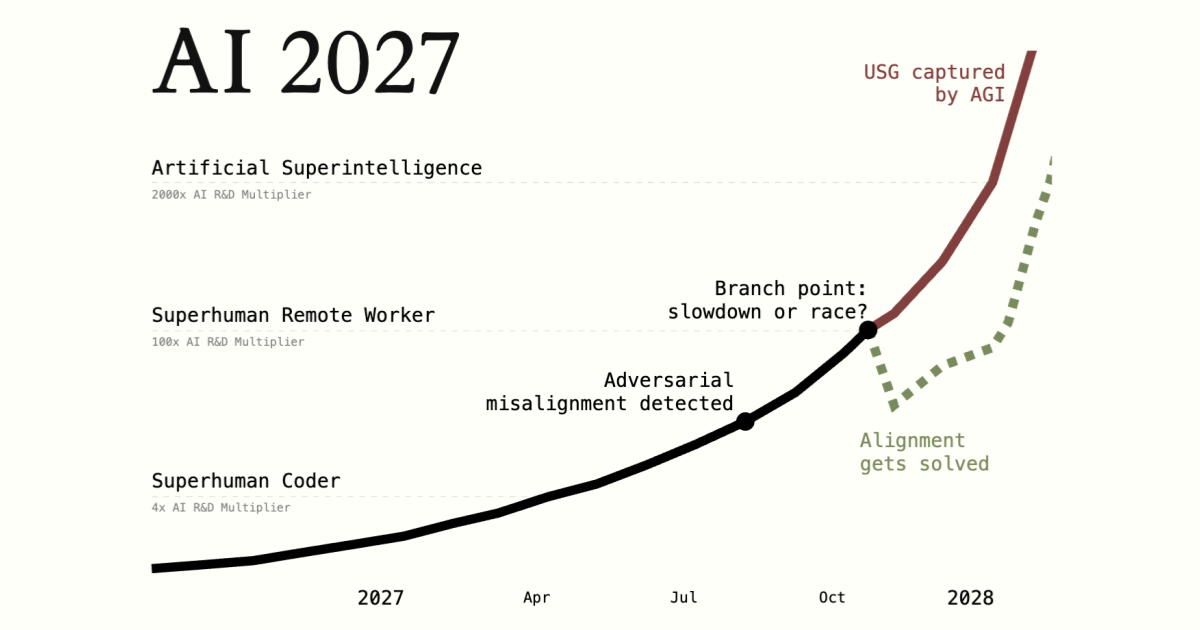
Educational videos on why people take SI risk seriously:
Rational animations (many relevant videos): What happens if AI just keeps getting smarter?
Kurzgesagt: A.I Humanity's final invention
And finally, a summary of brand-new research showing how leading AI models can exhibit dramatic self-preservation behavior...
Species | Documenting AGI: It Begins: An AI Literally Attempted Murder To Avoid Shutdown



